No Token Left Behind: Demystifying Token-In-Token-Out in Miles
In agentic RL, a rollout is not a single generation. It is a chain of model calls, tool outputs, harness messages, and resumed generations. Token-In-Token-Out (TITO) is a design principle that addresses one critical source of training–inference mismatch in this process: whether the trainer evaluates the exact same token sequence that the inference engine consumed and produced during rollout. In this blog post, we aim to clarify how we define the TITO principle, why it is important in RL training, and how such principle is instantiated in the Miles framework.
Definition of TITO
In an agentic rollout, the model repeatedly interacts with an external environment. In a simplified setting, the model first receives a task description and generates tokens, which may include reasoning and a tool call. The agent runtime parses the tool call, sends it to the corresponding environment or tool backend, and returns the result as a new observation. The model then continues from that observation and may issue another tool call. This loop repeats until the task is complete.
Note that the process involves multiple separate calls to the inference engine, which people colloquially define as turns. In each turn, the engine is prompted with a token sequence and generates another token sequence. We say that the TITO principle is fulfilled if, for all , the total token sequence in turn (prompt + response) is a bit-perfect prefix of the prompt token sequence in turn . The idea is illustrated in the following diagram.
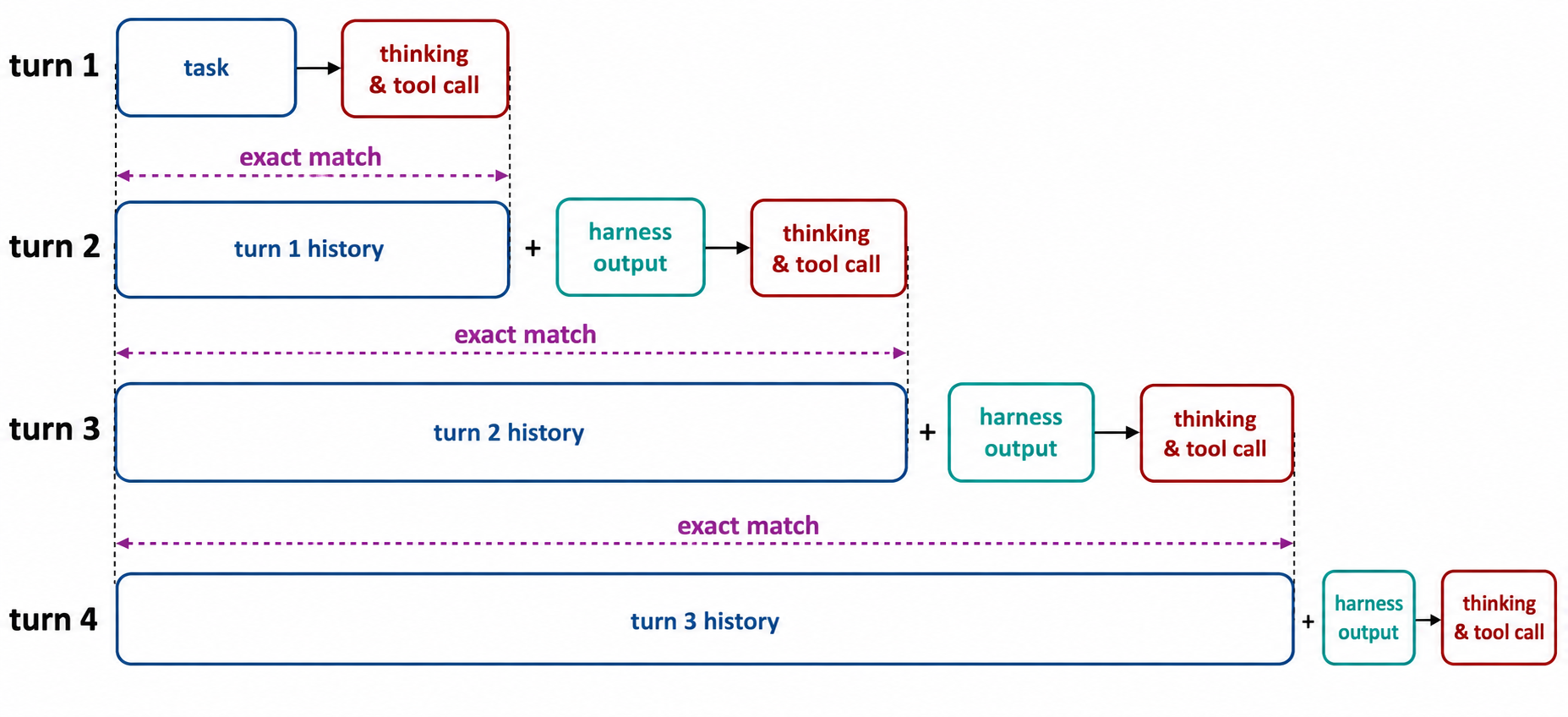
Why TITO matters?
Training Efficiency: One Sample Per Task
In agentic RL, where a single task can have dozens of turns, we essentially have two options to package data for the RL trainer:
- One Sample Per Turn: Each turn is treated as an independent training sample.
- One Sample Per Task: All turns are "glued" together into a single, contiguous sequence.
Let us compare both options. In option 1, the trainer receives as many samples as there are turns in a trajectory; whereas in option 2, the trainer always receives one sample per task instantiation, regardless of the number of turns. For a typical SWE-Bench-like task, a trajectory consists of 30-50 turns, which means that to ingest the same amount of information, option 2 only has to spend an order of magnitude less compute compared with option 1. Such massive reduction in compute cost makes option 2 especially appealing for scaling up agentic RL training.
Mathematical Correctness: Maintaining On-Policyness
For a training sample to be on-policy, every sampled token should be evaluated by the trainer under the same conditional distribution that produced it during rollout. In transformers, that conditional distribution is entirely dependent on the preceding context of the token. If TITO is violated, there could be a token such that
- In the trainer, the model evaluates based on the preceding sequence .
- In the inference engine, the model samples based on a slightly different preceding sequence .
Even if the trainer and the inference engine share identical weights, the conditional probability can diverge dramatically from . Such discrepancy can eventually lead to erratic updates, jeopardizing the stability of RL training.
How TITO might break
Despite its conceptual simplicity, the TITO principle is fragile. In what follows, we provide three common scenarios, among many others, where the principle could be violated.
Scenario 1: Detokenize-retokenize mismatch
In multi-turn RL rollouts, one might detokenize the model's generated tokens into a string for storage, and subsequently retokenize it when building the prompt for turn . This can potentially break the TITO principle because model-generated tokens cannot necessarily survive a detokenize-retokenize roundtrip.
The root cause lies in the asymmetry between how a tokenizer encodes text and how a model generates tokens:
encode(text → tokens) is one-to-one: For a given input string, the tokenizer always picks one standard split (typically greedy / longest-match).decode(tokens → text) is many-to-one: Multiple different token sequences can decode to the exact same string. The model can, and sometimes will, generate a valid but non-standard token sequence.
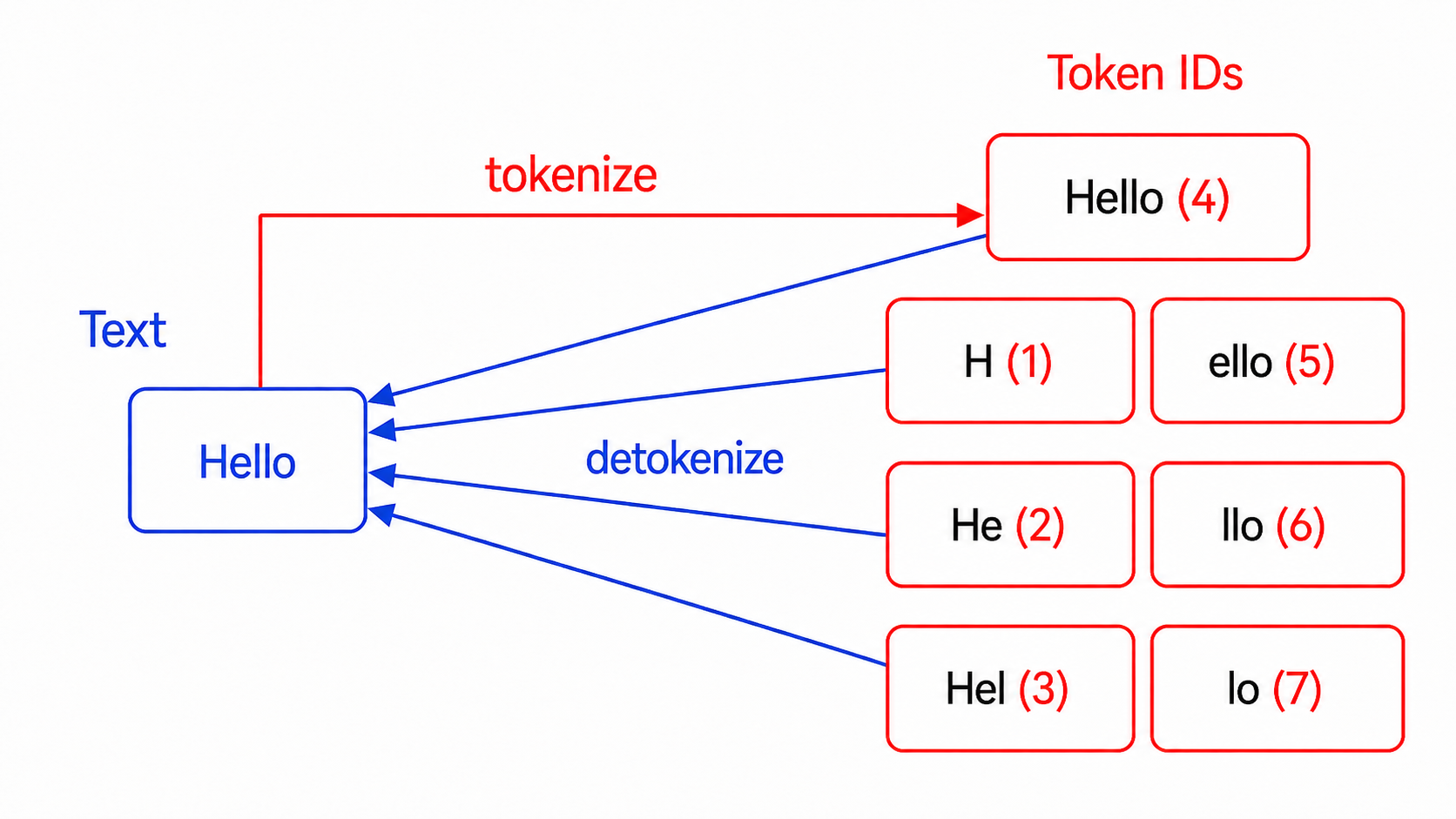
Example: Suppose the model generates two separate tokens Hel(3) and lo(7). Decoding them produces the string "Hello". However, when you re-encode "Hello", the tokenizer will canonically encode it as the single token Hello(4). The original Hel(3) + lo(7) sequence is lost forever, causing the trainer to evaluate a token sequence that the model never actually sampled.
Scenario 2: Reasoning pruned by chat templates
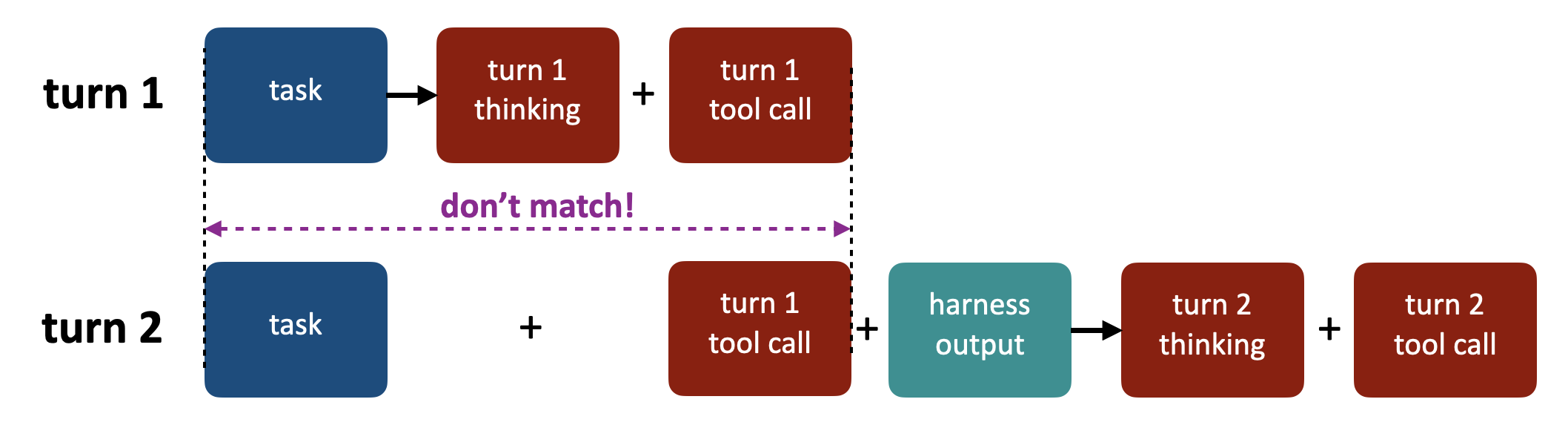
Chat templates translate a JSON-like list of messages into a single prompt string to be sent to the inference engine. Some reasoning-model templates introduce what we call a cut-thinking boundary: a point in the conversation before which historical assistant reasoning is removed from the rendered prompt. In the default chat templates of reasoning models like Qwen3 and Kimi K2, this boundary is determined by the last User message. When the template renders the conversation, it drops Assistant reasoning that appears before the last User message and preserves only the reasoning after that boundary.
However, agentic harnesses often inject User messages mid-task — for example, the Terminus-2 harness uses User for terminal outputs, while other harnesses use it for engine retries like "Parse failed". Each injection pushes the cut-think boundary forward, silently erasing the reasoning that the model actually sampled, breaking the bit-perfect prefix between turns. This behavior is illustrated below.
Scenario 3: Lossy chat-template re-rendering
Many inference engines accept a list of messages and re-apply the chat template plus tokenizer on every call to build the prompt. This is convenient, but dangerous: chat templates do their work at the string level — whitespace trimming, escape handling, reasoning-content repacking — so the token IDs they emit for a given message can depend on when and alongside what the message is rendered.
So re-applying the chat template at the message level also introduces unexpected text drift. Here is a concrete failure mode. In turn the assistant emits a tool call whose streamed tokens decode to a compact JSON body — no spaces after commas or colons, keys in the order the model chose:
{"name":"bash","arguments":{"cmd":"ls"}}
The engine parses this string and stores it as a structured tool_calls field on the assistant message. In turn , when the template re-renders the conversation, it serializes tool_calls back through a tojson filter. Because this parse-then-serialize roundtrip inherently discards the original byte-level formatting (spaces, newlines), the filter applies its own default spacing and emits:
{"name": "bash", "arguments": {"cmd": "ls"}}
Note the extra space after every comma and colon. Same semantics, different bytes, different token IDs. This breaks the bit-perfect prefix.
How TITO is implemented in Miles
Miles instantiates TITO with four components, designed so that the core invariant is mechanically verified and new models are cheap to onboard.
(1) Inference session server
An inference session is a single trajectory's interaction with the inference engine — the sequence of turns belonging to the same task, sharing one growing token buffer. The inference session server is a thin server layer that maintains per-trajectory state, keyed by session id. Under each id it holds a growing token buffer P that is appended in place every turn. The token buffer preserves each sample's exact token-level info (logprobs, routed experts), so it can be sent directly to training.
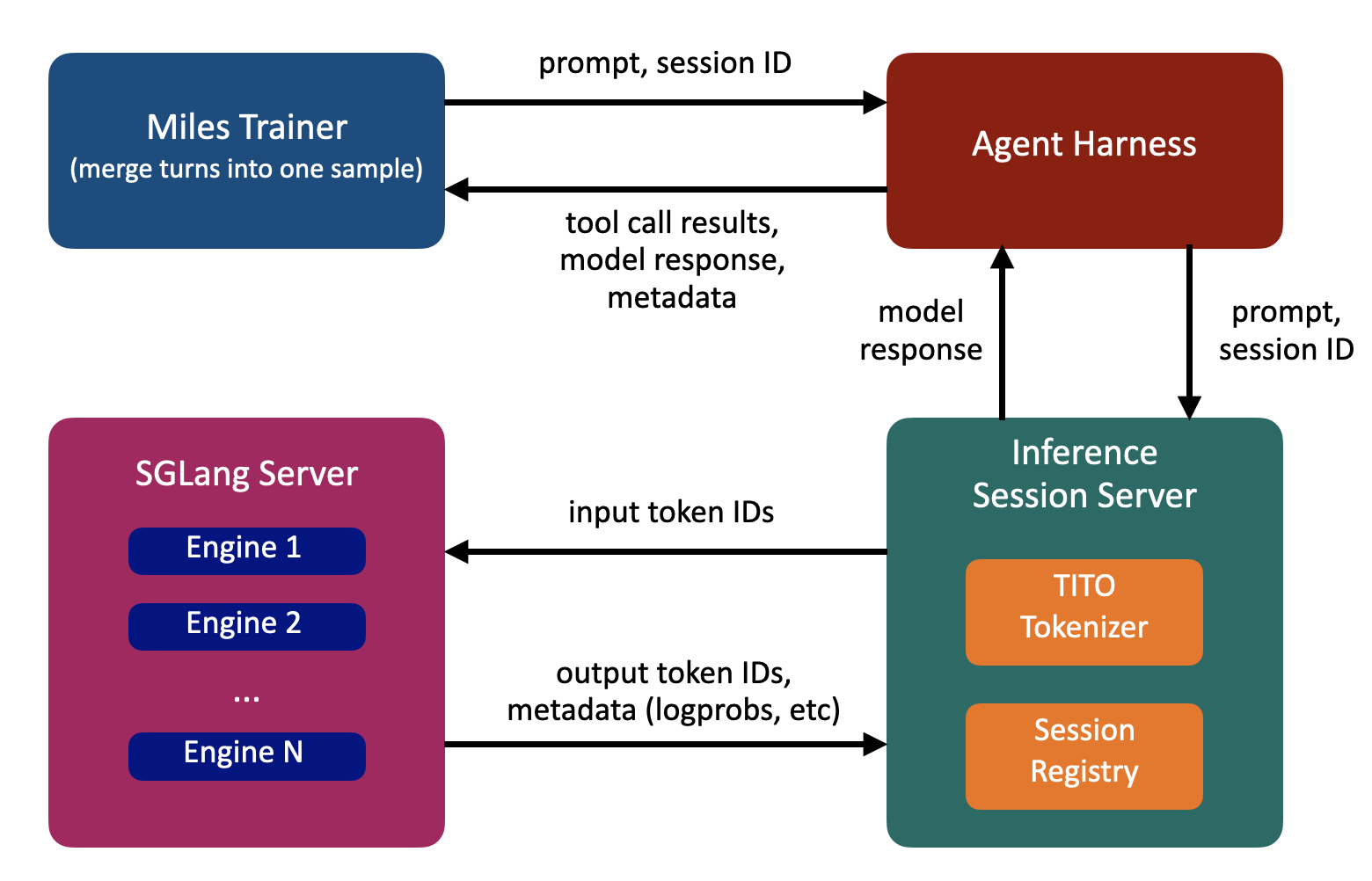
TITO inference session server flow.
(2) Ensure append-only at three levels
Append-only means each turn extends the previous turn's data without rewriting any earlier bytes. Miles enforces this at three levels:
Level 1 — message list. Turn 's message list extends turn 's with new messages on the tail; earlier message dicts are never mutated.
Level 2 — chat-template rendering. A chat template can break append-only by pruning earlier content (Scenario 2) or by rendering differently depending on which message roles the harness has appended. To prevent pruning, Miles ships fixed jinja templates that disable cut-thinking via a clear_thinking: false kwarg, preserving historical reasoning across turns. To prevent role-dependent rendering drift, users declare the expected appended roles via --tito-allowed-append-roles, and Miles auto-selects a prefix-stable template configuration for that role set.
Level 3 — token sequence. Tokenizing those renderings must produce a bit-perfect token prefix as per the definition of TITO. Naive retokenization breaks this even when Level 2 holds. Miles avoids retokenization entirely: each turn, only the newly appended messages are tokenized and the resulting IDs are appended in place. The pluggable TITO tokenizer described in the next section is what makes this append-only tokenization work.
(3) A pluggable TITO tokenizer
The TITO tokenizer is responsible for extending P — the per-trajectory token buffer maintained by the inference session server — whenever the harness appends a new non-assistant message. It computes the incremental tokens to splice onto P, plus the boundary patches some models need at the splice point.
Basic idea — dummy-prefix incremental tokenize. The recipe (inspired by this blog post) is:
- Build a synthetic minimal context.
- Render the chat template once with the new message and once without.
- Encode the byte difference.
The resulting delta gives the new serialized content, from which Miles derives the incremental tokens to append to P.
For example, suppose P already holds the tokenized prefix through turn and the harness now appends one tool response:
old_messages = [system, user, assistant]
new_messages = old_messages + [
{"role": "tool", "content": "file1.txt\nfile2.txt"},
]
Using Qwen3's template as an example, the byte difference for that tool response is:
<|im_start|>user
<tool_response>
file1.txt
file2.txt
</tool_response><|im_end|>
Encoding that gives the incremental tokens to append onto P.
Splice-point patches. The basic recipe, introduced above, assumes the tokens the engine put into P already match what the canonical template would render at that point. However, real models often violate that assumption and need small per-model patches at the splice point, which Miles handles via a hook in our TITO tokenizer:
- Qwen3. The model stops at
<|im_end|>, but the chat template ends every turn with<|im_end|>\n, soPis missing the trailing newline token. Miles appends the missing\ntoken before splicing the incremental tokens. - GLM-4.7. The model samples
<|user|>or<|observation|>as both stop and next-message-start tokens, and the harness may inject a different role next, leaving the wrong boundary token at the end ofP. Miles overwrites that wrong boundary token with the correct one for the incoming role — with the loss mask of the replaced position zeroed out so the swap is not trained on — before splicing the incremental tokens.
The following diagrams illustrate how the splice-point patches work for Qwen3 and GLM-4.7.
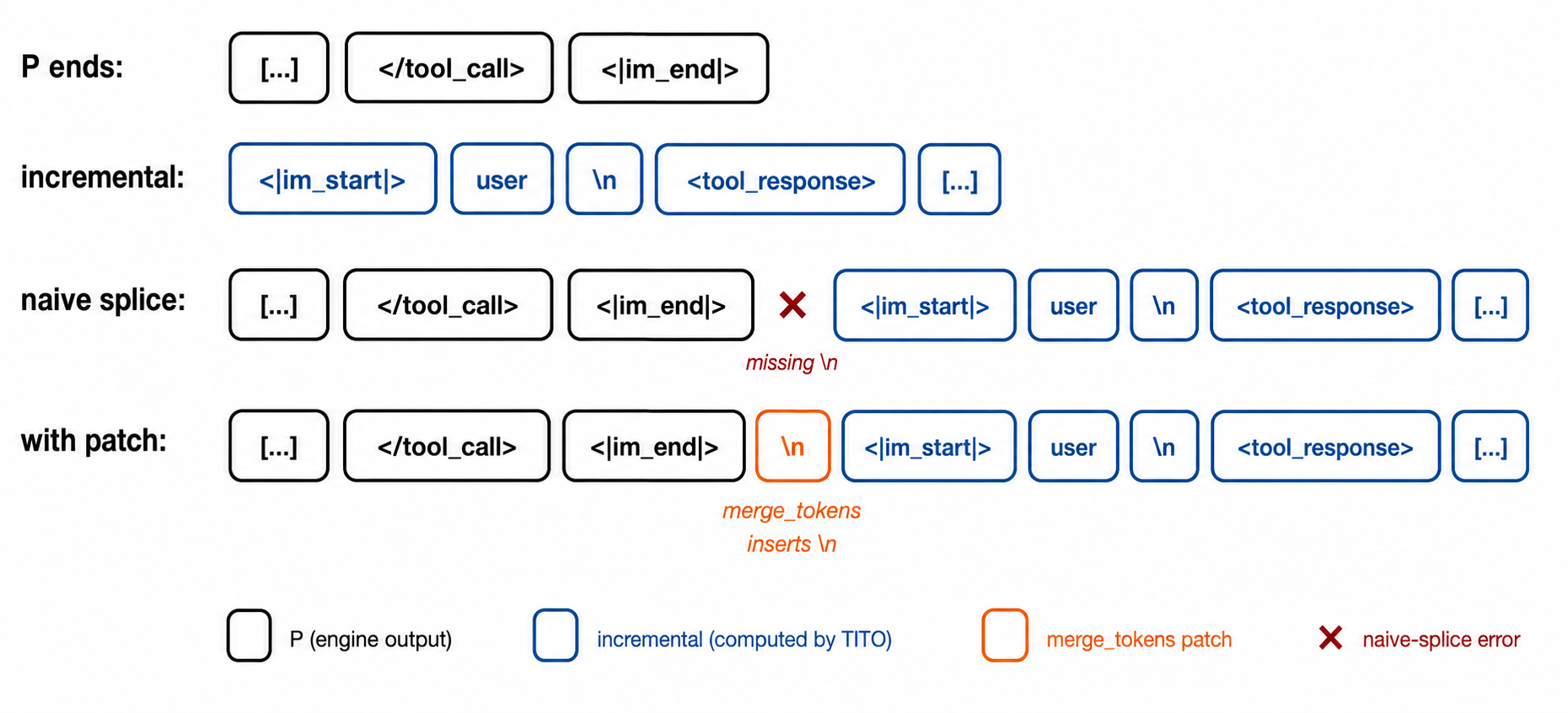
Qwen3 splice-point patch. The engine stops at <|im_end|>, but the canonical chat template ends every turn with <|im_end|>\n. Miles appends the missing \n to P before splicing the incremental tokens for the next message.
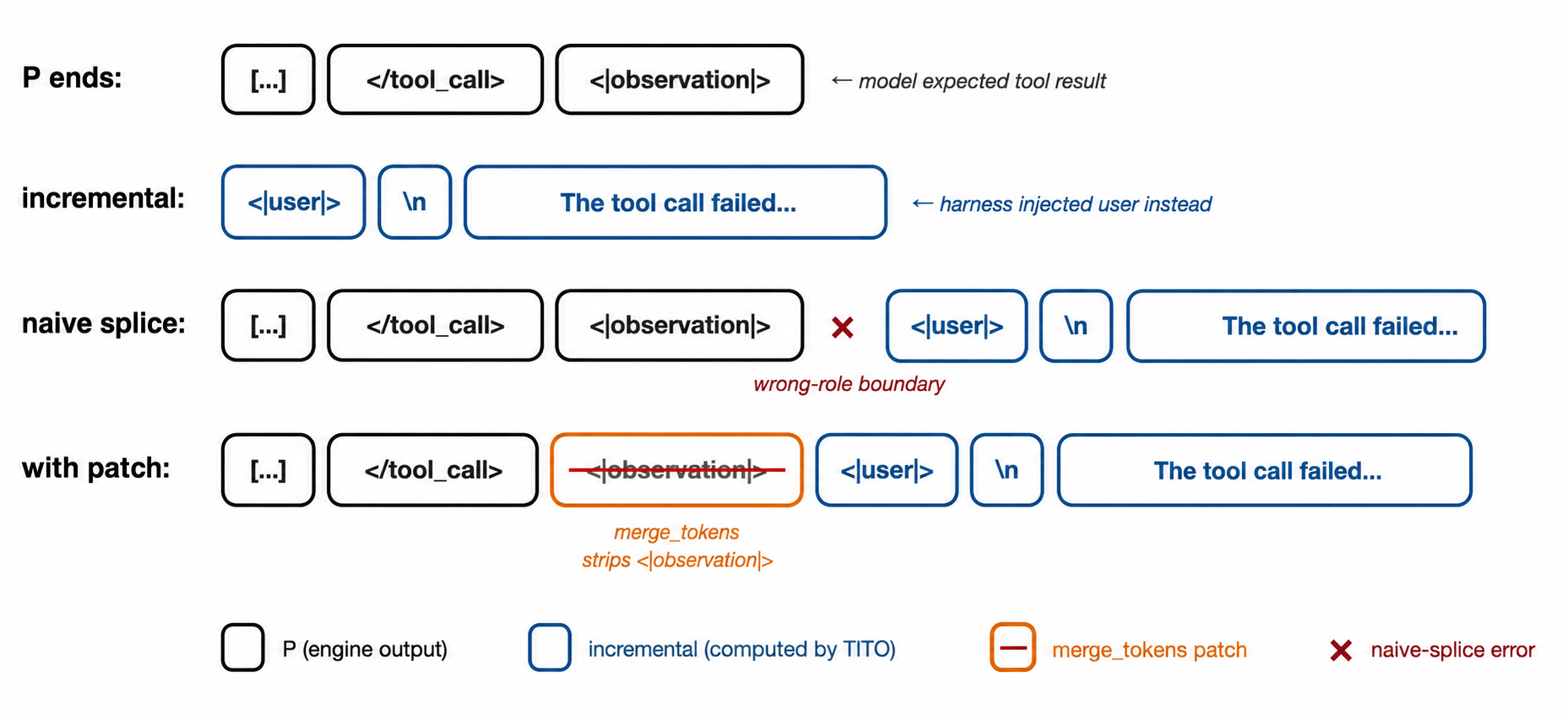
GLM-4.7 splice-point patch. The model samples <|user|> or <|observation|> as both stop and next-message-start tokens, but the harness may inject a different role next. Miles overwrites the wrong boundary token in P with the correct one for the incoming role (loss-masked to zero so it is not trained on) before splicing the incremental tokens.
(4) Verification via a token-sequence comparator
After each rollout we check that the token buffer P matches what the chat template would produce if we rendered the full message list from scratch. If P differs, the trainer is reading a context the model never actually saw — training silently drifts off-policy. Miles ships TokenSeqComparator to run this check.
Let actual be P and expected be the tokens we get by re-rendering the message list through the chat template. We can't just compare them token-by-token: per Scenario 1, the same text can encode to different token IDs, so a strict equality check would flag harmless retokenizations as failures.
To skip those harmless retokenizations while still catching real bugs, Miles uses a hybrid text-token check:
- Structural check: split
actualandexpectedat message-boundary special tokens (e.g.,<|im_start|>/<|im_end|>for Qwen3, but not<think>/</think>) and verify the two special-token sequences match. - Textual check: decode the segments between special tokens back to text and compare the strings, so retokenization differences that decode to identical text pass.
Even with the above checks, the model can still produce output that diverges from the chat template's expected format. A few common ways in which Assistant text consistency can break include:
- Spaces or newlines around tool-call boundaries (Scenario 3)
- Unclosed
<think>blocks - Stripping or extra newlines around
<think> - Early stopping caused by pad tokens
<|end_of_text|>
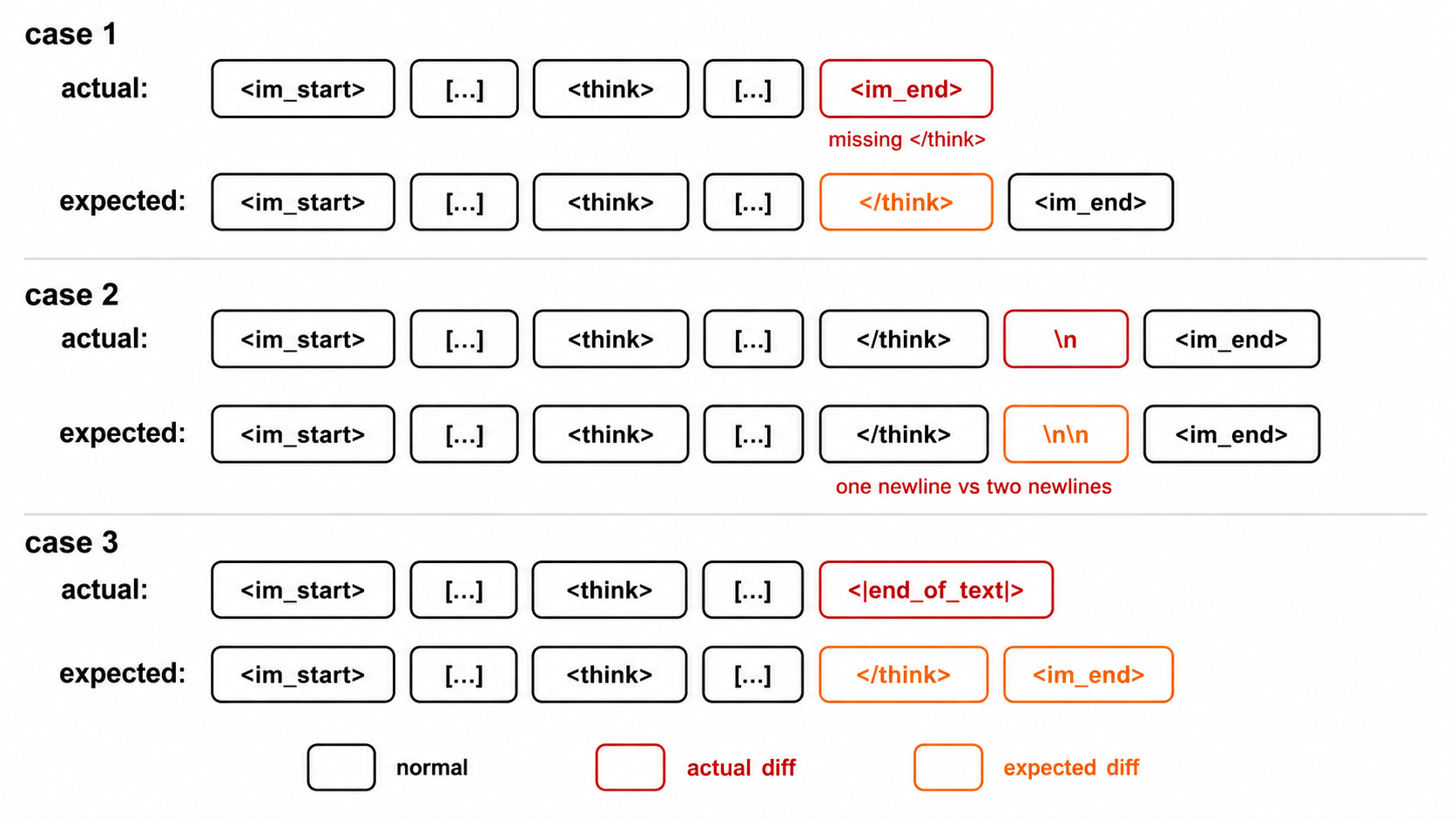
Because of such cases, mismatches in assistant tokens are unavoidable; Miles logs them and marks them non-critical. All other mismatches — special-token sequences and non-assistant text — must stay at zero, since those regions are deterministic and any divergence indicates a real bug in TITO.
Two verification scripts run this comparator across all supported (model, append-role-set) combinations: a CPU/fast layer on rendered token sequences, and a GPU/e2e layer that repeats the check under real model inference. Either failing blocks the change before it reaches training.
Supported Models
The TITO pipeline currently supports the following models natively (thinking & non-):
- Qwen: Qwen3, Qwen3.5, Qwen3-Next
- GLM: GLM-4.7, GLM-5
- Kimi: Kimi-K2, Kimi-K2.5, Kimi-K2.6
- Nemotron: Nemotron-3
- Minimax: Minimax-M2.5, Minimax-M2.7
- Deepseek: Deepseek-v3.2
For each model, TITO is verified to handle the following combinations of message roles a harness may append after the first assistant turn:
{tool}: harnesses that only inject tool outputs.{tool, user}: harnesses that also injectUser-role messages such as terminal outputs (e.g., Terminus-2) or parser-retry prompts.{tool, user, system}: harnesses that further injectSystem-role reminders mid-task.
Adding a new model is usually a fixed Jinja template plus a small merge_tokens override.